KNN
KNN is one of the simplest ML algorithms, it assigns a label to the new data based on the distance of the old & new data.
it's used for both regression and classification tasks.
when we use KNN we always keep in my mind 2 things :
1- choosing k-value
2- scale the features
Choosing the Optimal K-value :
I) Basic Case: K=1
This means the label assignment would be based on the nearest neighbor's distance.
The new data would be assigned a label same as the nearest class.
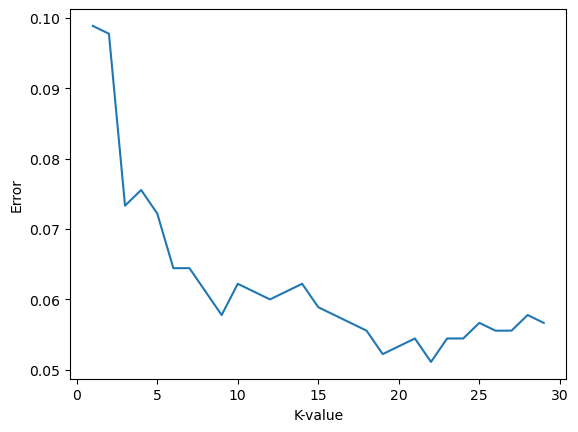
II) Using the Elbow Method:
Plot the error on the y-axis and the set of k-values on the x-axis.
Error is calculated as 1 - Accuracy (since accuracy measures how often our model predicted correctly).
Important Note:
The elbow method measures performance related to the chosen k-value based on the current train-test split and isn't an indication that the chosen k-value is optimal for all splits.
Keep in mind we need to trade off between how complex our model is and how much we need to minimize error.
Example Trade-off Question:
K-value = 20 & Error = 0.06
K-value = 6 & Error = 0.05
Which trade-off would you choose?
III)Using Grid Search Cross Validation (with pipeline):
This method is more feasible than the elbow method as our chosen k-value would be optimal for all splits.
Remember: Grid Search searches through the entire dataset to find the average error.
Cross-validation splits the dataset into parts (train, evaluation, test). Once we finalize our choice, we can then compare our performance to the test portion.
Scale the Features:
It’s essential to scale our features in KNN as it is a distance-based algorithm.
